Application of Hybrid CTC/2D-Attention end-to-end Model in Speech Recognition During the COVID-19 Pandemic
Introduction
Speech recognition technology is one of the important research directions in the field of artificial intelligence and other emerging technologies. Its main function is to convert a speech signal directly into a corresponding text. Yu Dong, et al. [1] proposed deep neural network and hidden Markov model, which has achieved better recognition effect than GMM-HMM system in continuous speech recognition task [1]. Then, Based on Recurrent Neural Networks (RNN) [2,3] and Convolutional Neural Networks (CNN) [4-9], deep learning algorithms are gradually coming into the mainstream in speech recognition tasks. And in the actual task they have achieved a very good effect. Recent studies have shown that endto- end speech recognition frameworks have greater potential than traditional frameworks. The first is the Connectionist Temporal Classification (CTC) [10], which enables us to learn each sequence directly from the end-to-end model in this way. It is unnecessary to label the mapping relationship between input sequence and output sequence in the training data in advance so that the endto- end model can achieve better results in the sequential learning tasks such as speech recognition. The second is the encodedecoder model based on the attention mechanism. Transformer [11] is a common model based on the attention mechanism. Currently, many researchers are trying to apply Transformer to the ASR field. Linhao Dong, et al. [12] introduced the Attention mechanism from both the time domain and frequency domain by applying 2D-attention, which converged with a small training cost and achieved a good effect.
And Abdelrahman Mohamed [13] both used the characterization extracted from the convolutional network to replace the previous absolute position coding representation, thus making the feature length as close as possible to the target output length, thus saving calculation, and alleviating the mismatch between the length of the feature sequence and the target sequence. Although the effect is not as good as the RNN model [14], the word error rate is the lowest in the method without language model. Shigeki Karita, et al. [15] made a complete comparison between RNN and Transformer in multiple languages, and the performance of Transformer has certain advantages in every task. Yang Wei, et al. [16] proposed that the hybrid architecture of CTC+attention has certain advancement in the task of Mandarin recognition with accent. In this paper, a hybrid end-to-end architecture model combining Transformer model and CTC is proposed. By adopting joint training and joint decoding, 2DAttention mechanism is introduced from the perspectives of time domain and frequency domain, and the training process of Aishell dataset is studied in the shallow encoder-decoder network.
Hybrid CTC/Transformer Model
The overall structure of the hybrid CTC/Transformer model is shown in (Figure 1). In the hybrid architecture, chained chronology and multi-head Attention are used in the process of training and grading, and CTC is used to restrain Attention and further improve the recognition rate. In end-to-end speech recognition task, the goal is through a network, the input 𝑥 = (𝑥1, … , 𝑥𝑇), calculate all output tags sequence 𝑦 = (𝑦1, … , 𝑦𝑀) corresponding probability, usually 𝑀 ≤ 𝑇, 𝑦 𝑚 ∈ 𝐿, 𝐿 is a finite character set, the final output is one of the biggest probability tags sequence, namely
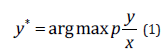
Connectionist Temporal Classification
Connectionist Temporal Classification structure as shown in (Figure 2), in the training, can produce middle sequence 𝜋 = (𝜋1, … , 𝜋𝑂), in sequence 𝜋 allow duplicate labels, and introduce a blank label 𝑏𝑙𝑎𝑛𝑘: < −> have the effect of separation, namely 𝜋 𝑖 ∈ 𝐿 𝖴 {𝑏𝑙𝑎𝑛𝑘}. For example 𝑦 = (我, 爱, 你, 中, 国), 𝜋 = (−, 我, −, −, 爱, 爱, −, 你, 你, −, 中, 国, −), 𝑦′ = (−, 我, −, 爱, −, 你, −, 中, −, 国, −), this is equivalent to construct a many- to-one mapping 𝐵: 𝐿′ → 𝐿≤𝑇 , The 𝐿≤𝑇 is a possible 𝜋 output set in the middle of the sequence, and then get the probability of final output tag:
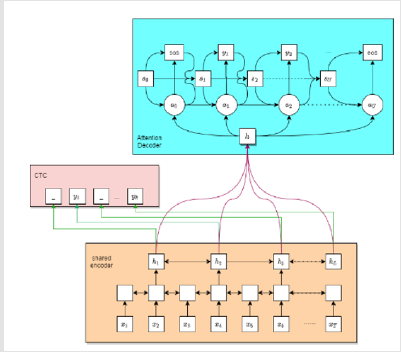
Figure 1:An encoder-decoder architecture based on Transformer and CTC .
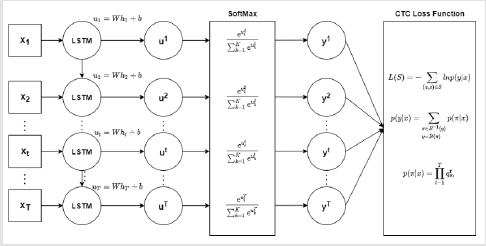
Figure 2:Connectionist Temporal Classification.
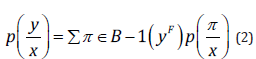
Where, 𝑆 represents a mapping between the input sequence and the corresponding output label; qπtt represents label πt at time 𝑡 corresponding probability. All tags sequence in calculation through all the time, because of the need to Nt iteration, 𝑁 said tag number, the total amount of calculation is too big. HMM algorithm can be used for reference here to improve the calculation speed:
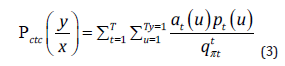
Among them, the 𝛼𝑡(𝑢) 𝛽𝑡(𝑢) respectively are forward probability and posterior probability of the 𝑢-th label at the moment 𝑡 to. Finally, from the intermediate sequence 𝜋 to the output sequence, CTC will first recognize the repeated characters between the delimiters and delete them, and then remove the delimiter <−>.
Transformer Model for 2D-Attention
Transformer model is used in this paper, which adopts a multilayer encoder-decoder model based on multi-head attention. Each layer in the encoder should be composed of a 2-dimensional multi-head attention layer, a fully connected network, and layer normalization and residual connection. Each layer in the decoder is composed of a 2-dimensional multi-head attention layer that screens the information before the current moment, an attention layer that calculates the input of the encoder, a three-layer network that is fully connected, and a layer normalization and residual connection. The multi-head attention mechanism first initializes the three weight matrices
𝑄. 𝐾. 𝑉 by means of linear transformation of the input sequence
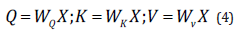
Then the similarity between the matrix 𝑄 and K is calculated by dot product:
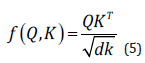
In the process of decoder, requiring only calculated before the current time and time characteristics, the similarity between the information on subsequent moment for shielding, usually under the introduction of a triangle total of 0 and upper triangular total negative infinite matrix, then, the matrix calculated by Equation (5) is transformed into a lower triangular matrix by replacing the negative infinity in the final result with 0. Finally, Softmax function is used to normalize the output results, and weighted average calculation is carried out according to the distribution mechanism of attention:
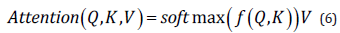
Multi-head attention mechanism actually is to multiple independent attention together, as an integrated effect, on the one hand, can learn more information from various angles, on the one hand, can prevent the fitting, according to the calculation of long attention if the above results when the quotas when the quotas for 𝑛 𝑛 time calculation, then the final result stitching together, converted into a linear output:
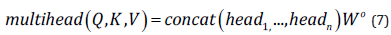
2D - Attention: The Attention structure in Transformer only models the position correlation in the time domain. However, human beings rely on both time domain and frequency domain changes when listening to speech, so the 2D-Attention structure is applied here, as shown in (Figure 3), that is, the position correlation in both time domain and frequency domain is modeled. It helps to enhance the invariance of the model in time domain and frequency domain.
Its calculation formula is as follows

After calculating the 2-dimensional multi-head attention mechanism, a feed-forward neural network is required at each layer, including a fully connected layer and a linear layer. The activation function of the fully connected layer is ReLU:
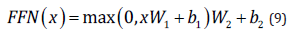
In order to prevent the gradient from disappearing, the residual connection mechanism should be introduced to transfer the input from the bottom layer directly to the upper layer without passing through the network, so as to slow down the loss of information and improve the training stability:
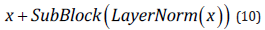
To sum up, the Transformer model with 2D-attention is shown in (Figure 4). The speech features are first convolved by two operations, which on the one hand can improve the model’s ability to learn time-domain information. On the other hand, the time dimension of the feature can be reduced to close to the length of the target output, which can save calculation and alleviate the mismatch between the length of the feature sequence and the target sequence.
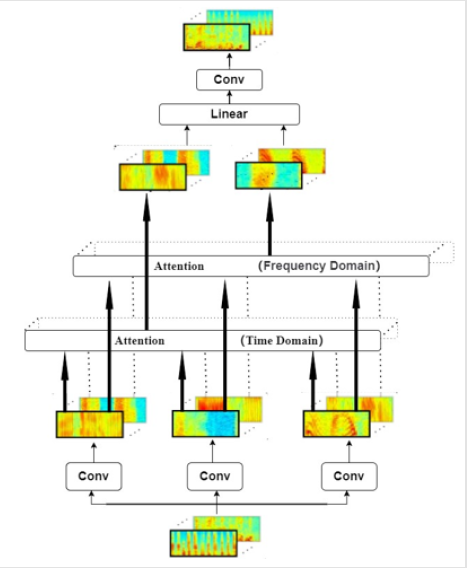
Figure 3:The structure of 2D-Attention.
The loss function is constructed according to the principle of maximum likelihood estimation:
The final loss function consists of a linear combination of CTC and Transformer’s losses:
FBANK Feature Extraction
The process of FBANK feature extraction is shown in (Figure 5). In all experiments, the sampling frequency of 1.6KHz and the 40-dimensional FBANK feature vector are adopted for audio data, 25ms for each frame and 10ms for frame shift.
Speech Feature Enhancement
In computer vision, there is a feature enhancement method called “Cutout” [17-20]. Inspired by this method, this paper adopts time and frequency shielding mechanism to screen a continuous time step and MEL frequency channel respectively. Through this feature enhancement method, the purpose of overfitting can be avoided. The specific methods are as follows
1. Frequency shielding: Shielding 𝑓 consecutive MEL frequency channels: [𝑓0, 𝑓0 + 𝑓), replace them with 0. Where, 𝑓 is from zero to custom frequency shielding parameters 𝐹 randomly chosen from a uniform distribution, and 𝑓0 is selected from [0, 𝑣 − 𝑓) randomly, 𝑣 is the number of MEL frequency channel.
2. Time shielding: Time step [𝑡0, 𝑡0 + 𝑡) for shielding, use 0 for replacement, including 𝑡 from zero to a custom time block parameters 𝑇 randomly chosen from a uniform distribution, 𝑡0 from [0, 𝑟 − 𝑡) randomly selected. The speech characteristics of the original spectra and after time and frequency shield the spectrogram characteristic of language contrast as shown in (Figure 6), to achieve the purpose of to strengthen characteristics.

Figure 4:Overall network architecture of Transformer model with 2D-Attention.
Figure 5:Flowchart of FBANK feature extraction.
Label Smoothing
The learning direction of neural network is usually to maximize the gap between correct labels and wrong labels. However, when the training data is relatively small, it is difficult for the network to accurately represent all the sample characteristics, which will lead to overfitting. Label smoothing solves this problem by means of regularization. By introducing a noise mechanism, it alleviates the problem that the weight proportion of the real sample label category is too large in the calculation of loss function, and then plays a role in inhibiting overfitting. The true probability distribution after adding label smoothing becomes:
Where K represents the total number of categories of multiple classifications, and 𝜀 is a small hyperparameter.
Experiment
Experimental Model
The end-to-end model adopted in this paper is a hybrid model based on Linked Temporalism and Transformer based on 2-dimensional multi-head attention. Compare the end-to-end model based on RNN-T and the model based on multiple heads of attention. The experiment was carried out under the Pytorch framework, the GPU RTX 3080.
Data
This article uses Hill Shell’s open source Aishell dataset, which contains about 178 hours of open-source data. The dataset contains almost 400 recorded voices from people with different accents from different regions. Recording was done in a relatively quiet indoor environment using three different devices: a high-fidelity microphone (44.1kHz, 16-bit); IOS mobile devices (16kHz, 16- bit); Android mobile device (16kHz, 16-bit) to record, and then by sampling down to 16kHz.
Network Structure and Parameters
The network in this paper uses four layers of multi-head attention, and the input attention dimension of each layer is 256, the input feature dimension of the forward full connection layer is 256, and the hidden feature dimension is 2048. The combined training parameter λ is 0.1, the rate of random loss of activated cells is 0.1, and the label smoothing is 0.1. The epoch times are 200.
Evaluation Index
In the evaluation of experimental results, word error rate (WER) was used as the evaluation index. Word error rate is identified primarily for the purpose of make can make between words and real words sequences of the same, the need for specific words, insert, substitute, or delete these insertion (I), substitution (S) or deletion (D) of the total number of words, divided by the real word sequence of all the percentage of the total number of words. namely
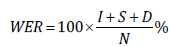
Experimental Results and Analysis
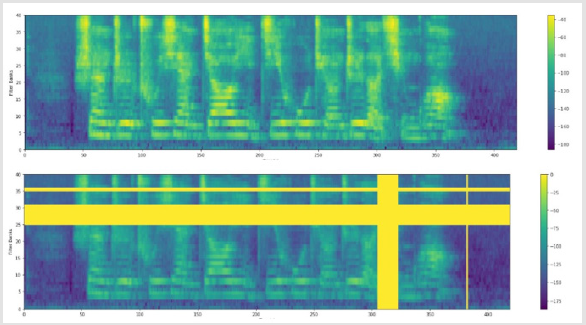
Figure 6:Feature enhancement contrast chart.
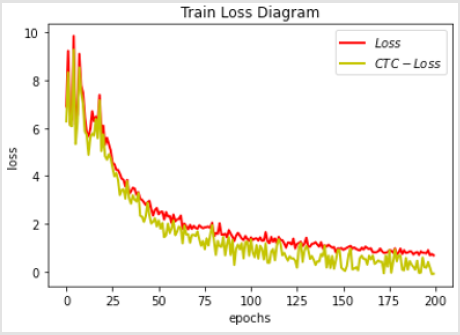
Figure 7:Contrast chart of loss changes.
(Table 1) shows the comparison between the 2D-attention model without CTC and the 2D- attention model with CTC. Compared with the ordinary model, the performance of the model with CTC is improved by 6.52%-10.98%, and the word error rate of the end-toend model with RNN-T is reduced by 4.26%. Performance improved by 37.07%. (Figure 7) shows the comparison of the loss functions of the two models (2D-attention model without CTC and 2D-attention model with CTC). Compared with the ordinary model, the loss of the constrained model with CTC can reach a smaller value.
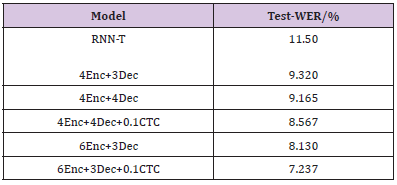
Table 1: Comparison of model word error rate.
Conclusion
In this paper, we propose a hybrid architecture model of Transformer using CTC and 2- dimensional Multi-head Attention to apply to Mandarin speech recognition. Compared with the traditional speech recognition model, it does not need to separate the acoustic model and the language model to train, only needs to train a single model, from the time domain and frequency domain two perspectives to learn the speech information, can achieve advanced model recognition rate. It is found that compared with the end-to-end model of RNN-T, the performance of Transformer model is better, and the increase in the depth of the encoder can better learn the information contained in the speech, which can significantly improve the performance of the model for Mandarin recognition, while the increase in the depth of the decoder has little effect on the overall performance of speech recognition. At the same time, by introducing a link of sequence alignment is improved, the model makes the model to achieve the best effect, but on some professional vocabulary is not accurate, the subsequent research by increasing solution of language model, at the same time, in view of the very deep network training speed slow problem, to improve and upgrade.
Acknowledgement
This work was supported by the Philosophical and Social Sciences Research Project of Hubei Edu cation Department (19Y049), and the Staring Research Foundation for the Ph.D. of Hubei University of Technology (BSQD2019054), Hubei Province, China.
| For more Articles on : https://biomedres01.blogspot.com/ |



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.