Machine Learning Analysis of a Chilean Breast Cancer Registry
Purpose
As occurs in several countries, breast cancer (BC) is one of
the leading causes of cancer related death among Chilean women
[1]. Like other malignancies, breast neoplasms are characterized
by their heterogeneity. This not only applies to clinical features of
patients but also, to molecular, genetic and histologic characteristics
[2]. Similarly, incidence rates and associated risk factors display a
marked geographic variability [1]. To date, several studies have
reported BC incidence and prevalence rates in both Europe and
North America. These studies have also reported clinical-genetic
characteristics and prognosis. In sharp contrast, South American
reports on these topics are scarce [3]. Indeed, only a few Latin
American studies have included data on limited populations, these
are mostly from Brazil and Mexico [4,5]. Unpublished data from our
group suggest that differences in lifestyle along with a diverse racial
background could explain particular characteristics observed in the
Chilean population.
In recent decades, Artificial Intelligence (AI) has emerged as an innovative and valuable tool in medicine, providing assistance to achieve more accurate patient diagnoses and to support making medical decisions. Interestingly, certain studies demonstrate that AI-algorithms can compete or even outperform clinicians in specific tasks [6]. In lay terms, AI-algorithms can be easily ‘trained’ by using sample data. Thus, algorithms “learn” to do their job much like doctors learn by attending medical school for years, making right decisions and sometimes mistakes. Within this context, Machine Learning (a form of AI) seeks to apply algorithms and build models based on training data in order to make predictions in a variety of applications including medicine [7]. In 1997 our institution started a longitudinal BC registry that included invasive disease cases. In recent years, our group has generated several publications focused on BC incidence, clinical characteristics of patients and clinical data based on these analyses [8-10]. Herein we report preliminary analyses on data applying machine learning to analyze our local BC patient registry.
Patients and Methods
This study was part of a collaborative effort between Hospital Sotero del Rio and Cancer Center at Pontificia Universidad Católica de Chile, the former a public hospital and the later a university cancer center, both at Santiago, Chile. We sought to determine relevant clusters of BC patients associated with clinical characteristics and survival that allow us to evaluate and propose patient-adapted therapeutic schemes. The K-medoids clustering algorithm was used to define a patient profile based on demographic (sex, age, weight / height, cancer family history, comorbidities and BC risk factors) and clinical-pathological information (stage, BC subtype, surgery, type of systemic treatment). Once the groups were separated, survival rates were calculated using the Kaplan-Meier method. This analysis allows us to link patient profiles with the behavior of survival rates. Then, data analytics methods were applied to determine the most relevant variables for each of the clusters and their correlation with survival rates. Finally, we estimate the time evolution of the treatments carried out (trajectories). In this way, it is possible to describe treatment schemes for each of the defined clustering.
Results
Overall, a total of 4838 registered BC patients were included into our study. Our analyses divided patients into five clusters with marked differences in clinical characteristics and prognoses see Figure 1. The key variables that defined these clusters included: age at diagnosis, body mass index, family history of cancer (by a first-degree relative), comorbidities (mainly hypertension), compromised nodes, and BC relapse. Clusters were also associated with significant differences in overall and disease-free survival (Figure 2).
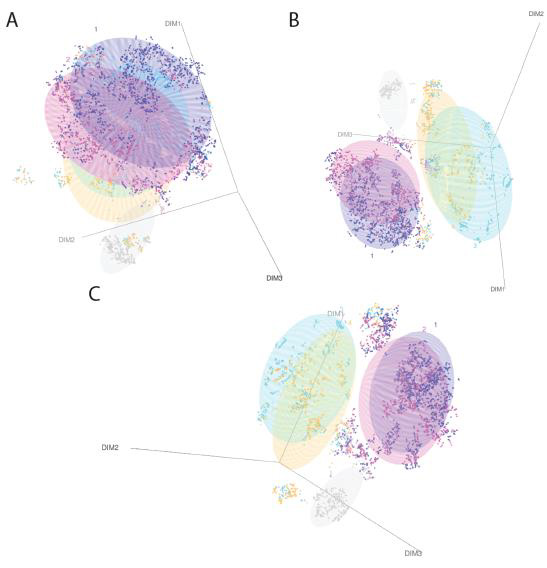
Figure 1: Graphical three-dimensional representation of the five clusters of patients generated by our model. Panels A, B and C show different angles.
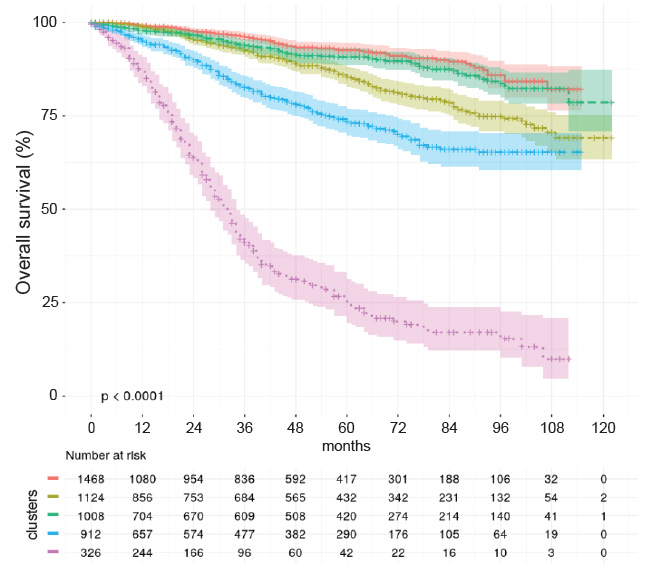
Figure 2: Overall survival for the identified clusters of patients.
Conclusion
To our knowledge, this is the first Latin American report
applying a machine learning approach to analyze BC registry data,
including clinical features and survival outcomes. Our findings
confirm the capacity of machine learning to differentiate BC
clusters with specific clinical and prognostic outcomes. Currently,
we are validating this approach and expanding our database.
For more Articles on : https://biomedres01.blogspot.com/



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.